La idea de este post es colocar en el mapa a Trino e instalarlo sobre un clúster de VMs en Azure. En realidad, es lo que me hubiera gustado encontrar hace unas semanas para ahorrarnos (a mí y a Alejandro García Miravet) un montón de prueba y error. Si alguien quiere probar Trino, espero que lo tenga un poco más fácil después de leer este post.
Trino is a distributed SQL query engine designed to query large data sets distributed over one or more heterogeneous data sources.
Lo que me llamó la atención es: primero, usar un mismo lenguaje para acceder a distintos orígenes de datos; segundo, usar un clúster para poder escalar en horizontal.
Además Trino permite ejecutar federated queries, esto es poder hacer join entre 2 tablas de 2 orígenes de datos distintos. Al final, podemos ver a Trino como un “data warehouse virtual”, donde sin necesidad de un ETL, tenemos una vista unificada de todos los datos de nuestra compañía.
Como curiosidad, a Trino también se le conoce como prestoSQL y hay una historia muy interesante detrás de la “rivalidad” entre prestodb y Trino.
En nuestro caso particular estamos evaluando Trino como alternativa a Spark y a Hive sobre ficheros .csv y .parquet en una cuenta de almacenamiento de tipo ADLS Gen2, y lo de Gen2 es importante.
Trino también está disponible como un servicio administrado en Azure a través de la empresa Startbust.
La arquitectura de Trino a alto nivel es bastante sencilla. Un clúster está formado por un coordinator y n workers. Un cliente conectará al coordinator para ejecutar una consulta SQL (a través de JDBC, ODBC, REST API o cualquiera de las librerías disponibles: Python, Go, Node, Ruby, etc). Después un conector leerá datos del origen (haciéndolo mejor o peor, en paralelo o no, todo ello según la implementación del propio conector) y finalmente, se procesará la consulta de forma distribuida en la memoria de los workers.
Personalmente, algo que me hizo mucho daño al comienzo fue pensar que Hive era necesario siempre en el coordinator. Sin embargo, sólo es necesario si vas a usar el conector de Hive para acceder a un object storage (por ejemplo ADLS o S3). En este post lo explican bastante bien y parece es una confusión bastante habitual.
El único problema que veo a Trino por ahora es que no hay un driver ODBC OOS (sí que hay JDBC). Startbust lo ofrece como parte de su servicio administrado y otras empresas como Magnitude también lo comercializan… pero no es barato, pregunté y me quedé muerto.
Si comparamos Spark con Trino, lo que estamos comparando es un framework, que hace muchas cosas y bien, contra un programa que sólo hace una cosa pero, en teoría, la hace mejor (right tool for the right job). Mis primeras impresiones (sin ningún rigor técnico) son que, efectivamente, la misma consulta se ejecuta más rápido en Trino. Por el contrario, si usas Spark en Databricks, no tendrás ningún problema con el driver ODBC y además la gestión del clúster y todo el ecosistema que le rodea es muy sencilla. Incluso el correcto dimensionamiento del clúster parece menos importante en Databricks porque Spark terminará usando mucho más el spill que Trino (spill es como un swap, volcar datos intermedios desde memoria a disco y vicerversa), y como se añadirán discos de forma automática al clúster, termina siendo muy cómodo no tener que hacer un ajuste tan fino de antemano como sí nos obligará a hacer Trino. También es cierto que hacer spill no es algo bueno, en un mundo ideal no debería pasar, la memoria es rápida, el IO a disco ya no tanto. En cualquier caso, no conviene olvidar que todo la magia de Databricks irá acompañada después de unos bonitos DBUs en la factura.
Para probar Trino en local, lo más sencillo es usar Docker con los catálogos tpch y tpcds que, en el caso de Trino, generan datos al vuelvo para simular una carga de tipo OLTP y OLAP.
docker run -d --name trino-getting-started -p 8080:8080 trinodb/trino # download trino image, run in the background and expose 8080 port
docker exec -it trino-getting-started trino # execute trino-client and attach interactive terminal
trino> SELECT * FROM tpch.sf1.customer; -- SELECT * FROM catalog.schema.table;
trino> exit
docker stop trino-getting-started # stop running container
docker rm trino-getting-started # remove container
docker rmi trinodb/trino # remove image
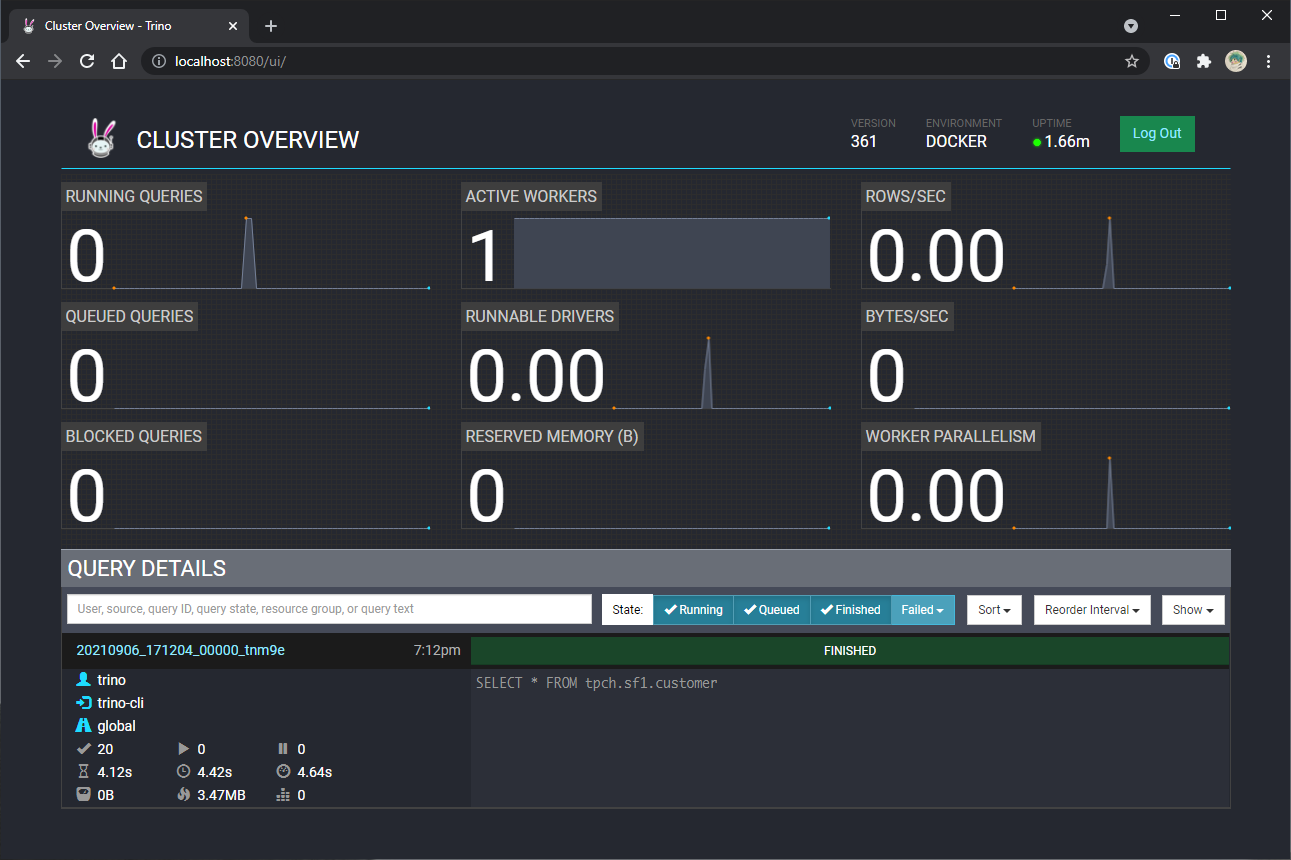
Parece claro que un clúster de 1 nodo no va a ser suficiente si queremos ver funcionar a Trino en todo su esplendor así que, dejando a un lado Docker, yo he optado por crear VMs en Azure porque además quería trastear un poco con Linux.
Con el fichero cluster.sh crearemos en Azure todo lo necesario para el clúster:
YOUR_SUBSCRIPION_IDYOUR_PASSWORDYOUR_PUBLIC_IP- Si tienes 2 o más IPs públicas sepáralas por espacios.
Es verdad que es mejor usar una clave privada que una contraseña para conectar por ssh, pero en un entorno de dev/testing, una contraseña facilita mucha la vida.
cluster.sh
#!/bin/bash
az login
subscription=YOUR_SUBSCRIPTION_ID
az account set --subscription $subscription
az group create --name rg-trino --location westeurope
az network nsg create --name nsg-trino --resource-group rg-trino
az network vnet create --name vnet-trino --resource-group rg-trino --network-security-group nsg-trino --subnet-name snet-trino
az network vnet subnet update --network-security-group nsg-trino --name snet-trino --resource-group rg-trino --vnet-name vnet-trino
az network public-ip create --name pip-vm-coordinator --resource-group rg-trino --allocation-method Static --sku Basic
image=canonical:0001-com-ubuntu-server-focal:20_04-lts:latest
size=Standard_DS1_v2
password=YOUR_PASSWORD
username=azureuser
storage_sku=Standard_LRS
az vm create --name vm-coordinator --resource-group rg-trino --image $image --size $size --admin-password $password --admin-username $username --authentication-type password --nsg '' --public-ip-address pip-vm-coordinator --subnet snet-trino --vnet-name vnet-trino --storage-sku $storage_sku
for i in {1..2} # choose your cluster size
do
az network public-ip create --name pip-vm-worker$i --resource-group rg-trino --allocation-method Static --sku Basic
az vm create --name vm-worker$i --resource-group rg-trino --image $image --size $size --admin-password $password --admin-username $username --authentication-type password --nsg '' --public-ip-address pip-vm-worker$i --subnet snet-trino --vnet-name vnet-trino --storage-sku $storage_sku
done
public_ip=YOUR_PUBLIC_IP
az network nsg rule create --name nsgsr-ssh --nsg-name nsg-trino --priority 300 --resource-group rg-trino --access Allow --direction Inbound --protocol Tcp --destination-port-ranges 22 --source-address-prefixes $public_ip
az network nsg rule create --name nsgsr-sql --nsg-name nsg-trino --priority 310 --resource-group rg-trino --access Allow --direction Inbound --protocol Tcp --destination-port-ranges 1433 --source-address-prefixes $public_ip
az network nsg rule create --name nsgsr-http --nsg-name nsg-trino --priority 320 --resource-group rg-trino --access Allow --direction Inbound --protocol Tcp --destination-port-ranges 8080 --source-address-prefixes $public_ip
Teniendo ya las VMs creadas, es hora de instalar los prerequisitos de Trino:
- Java.
- Python.
- Sólo en el coordinator (o en un nodo dedicado a ello en exclusiva) y si vas a usar el conector de Hive:
- Hive metastore standalone.
- Un RDBMS.
Hive necesita un BD externa porque de serie guarda los metadatos en memoria usando derby que no es apta para producción.
En mi caso, he optado por SQL Server. Para instalarlo, lo más sencillo es seguir los pasos de la documentación oficial. En cualquier caso y para Ubuntu 20.04, con lo siguiente bastaría:
wget -qO- https://packages.microsoft.com/keys/microsoft.asc | sudo apt-key add -
sudo add-apt-repository "$(wget -qO- https://packages.microsoft.com/config/ubuntu/20.04/mssql-server-2019.list)"
sudo apt-get update
sudo apt-get install -y mssql-server
sudo /opt/mssql/bin/mssql-conf setup
sudo apt-get update
sudo apt install curl
curl https://packages.microsoft.com/keys/microsoft.asc | sudo apt-key add -
curl https://packages.microsoft.com/config/ubuntu/20.04/prod.list | sudo tee /etc/apt/sources.list.d/msprod.list
sudo apt-get update
sudo apt-get install -y mssql-tools unixodbc-dev
echo 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bashrc
source ~/.bashrc
Para confirmar que SQL Server está funcionando correctamente, puedes ejecutar sqlcmd -S localhost -U SA -P 'YOUR_PASSWORD' y alguna consulta sencilla como SELECT @@VERSION;.
En cuanto al resto de prerrequisitos, con la ayuda de sshpass, ssh y scp intentaremos hacer la tarea un poco más llevadera.
El fichero que tienes que ejecutar en local es install_prerequisites.sh (que ejecutará en remoto prerequisites.sh y coordinator_prerequisites.sh), y habiendo reemplazado previamente YOUR_PASSWORD, YOUR_PUBLIC_COORDINATOR_IP, YOUR_PUBLIC_WORKER_IP_1, YOUR_PUBLIC_WORKER_IP_2 y así sucesivamente.
Puedes recuperar las IPs públicas de todos los nodos del clúster con el siguiente comando, siendo la primera IP la de vm-coordinator (por la ordenación alfabética):
az network public-ip list --query "sort_by([], &name)[?resourceGroup == 'rg-trino'].ipAddress"
install_prerequisites.sh
#!/bin/bash
password=YOUR_PASSWORD
public_ip_list=(YOUR_PUBLIC_COORDINATOR_IP YOUR_PUBLIC_WORKER_IP_1 YOUR_PUBLIC_WORKER_IP_2)
for public_ip in "${public_ip_list[@]}"
do
sshpass -p $password scp -r -o StrictHostKeyChecking=no prerequisites.sh azureuser@$public_ip:/home/azureuser/
sshpass -p $password ssh -o StrictHostKeyChecking=no azureuser@$public_ip 'chmod +x prerequisites.sh;./prerequisites.sh'
done
coordinator_public_ip=${public_ip_list[0]}
sshpass -p $password scp -r -o StrictHostKeyChecking=no coordinator_prerequisites.sh hive.sql azureuser@$coordinator_public_ip:/home/azureuser/
sshpass -p $password ssh -o StrictHostKeyChecking=no azureuser@$coordinator_public_ip 'chmod +x coordinator_prerequisites.sh;./coordinator_prerequisites.sh'
prerequisites.sh
#!/bin/bash
wget -q https://cdn.azul.com/zulu/bin/zulu11.50.19-ca-jre11.0.12-linux_x64.tar.gz -O zulu11.50.19-ca-jre11.0.12-linux_x64.tar.gz
tar -xzvf zulu11.50.19-ca-jre11.0.12-linux_x64.tar.gz
echo export JAVA_HOME=~/zulu11.50.19-ca-jre11.0.12-linux_x64 >> .bashrc
echo 'export PATH=$PATH:$JAVA_HOME/bin' >> .bashrc
sudo apt install python-is-python3
coordinator_prerequisites.sh
#!/bin/bash
wget -q https://repo1.maven.org/maven2/org/apache/hive/hive-standalone-metastore/3.1.2/hive-standalone-metastore-3.1.2-bin.tar.gz -O hive-standalone-metastore-3.1.2-bin.tar.gz
tar -zxvf hive-standalone-metastore-3.1.2-bin.tar.gz
wget -q https://downloads.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz -O hadoop-3.3.1.tar.gz
tar -zxvf hadoop-3.3.1.tar.gz
echo export HADOOP_HOME=~/hadoop-3.3.1 >> .bashrc
echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> .bashrc
echo export HIVE_HOME=~/apache-hive-metastore-3.1.2-bin >> .bashrc
echo 'export PATH=$PATH:$HIVE_HOME/bin' >> .bashrc
cp hadoop-3.3.1/share/hadoop/tools/lib/*azure*.jar hadoop-3.3.1/share/hadoop/common/lib/
cp hadoop-3.3.1/share/hadoop/tools/lib/wildfly-openssl-1.0.7.Final.jar hadoop-3.3.1/share/hadoop/common/lib/
/opt/mssql-tools/bin/sqlcmd -S localhost -U SA -P YOUR_PASSWORD -i hive.sql
wget -q https://download.microsoft.com/download/b/c/5/bc5e407f-97ff-42ea-959d-12f2391063d7/sqljdbc_9.4.0.0_enu.tar.gz -O sqljdbc_9.4.0.0_enu.tar.gz
tar -xzvf sqljdbc_9.4.0.0_enu.tar.gz
cp sqljdbc_9.4/enu/mssql-jdbc-9.4.0.jre8.jar ~/apache-hive-metastore-3.1.2-bin/lib
Con hive.sql (y reemplazando previamente YOUR_PASSWORD) crearemos un base de datos vacía para usar después con Hive.
CREATE DATABASE hive;
GO
CREATE LOGIN hive WITH PASSWORD = 'YOUR_PASSWORD';
GO
USE hive;
GO
CREATE USER hive FOR LOGIN hive; -- public
GO
ALTER ROLE db_owner ADD MEMBER hive;
GO
Antes de pedir a Hive que cree todo lo necesario dentro de la base de datos recién creada, es necesario en el coordinator el fichero de configuración /home/azureuser/apache-hive-metastore-3.1.2-bin/conf/metastore-site.xml, siendo YOUR_PASSWORD el que especificamos en hive.sql.
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:sqlserver://localhost:1433;DatabaseName=Hive;</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.microsoft.sqlserver.jdbc.SQLServerDriver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>YOUR_PASSWORD</value>
</property>
<property>
<name>metastore.thrift.uris</name>
<value>thrift://localhost:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
<property>
<name>metastore.task.threads.always</name>
<value>org.apache.hadoop.hive.metastore.events.EventCleanerTask</value>
</property>
<property>
<name>metastore.expression.proxy</name>
<value>org.apache.hadoop.hive.metastore.DefaultPartitionExpressionProxy</value>
</property>
</configuration>
Ahora podemos ejecutar el script de inicialización de Hive con schematool.
schematool -dbType mssql -initSchema
Para acceder con Hive a nuestra cuenta de almacenamiento en Azure tendremos que crear un Service Principal y darle permisos de Storage Blob Data Owner. Además hay que incluir lo siguiente en el fichero metastore-site.xml, prestando atención a fs.azure.account.oauth2.client.endpoint que tiene ser la versión 1 del endpoint de token (no vale la 2). La documentación de este fichero está aquí.
<property>
<name>fs.azure.account.auth.type</name>
<value>OAuth</value>
</property>
<property>
<name>fs.azure.account.oauth.provider.type</name>
<value>org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider</value>
</property>
<property>
<name>fs.azure.account.oauth2.client.endpoint</name>
<value>YOUR_OAUTH_20_TOKEN_ENDPOINT_V1</value>
</property>
<property>
<name>fs.azure.account.oauth2.client.id</name>
<value>YOUR_CLIENT_ID</value>
</property>
<property>
<name>fs.azure.account.oauth2.client.secret</name>
<value>YOUR_SECRET</value>
</property>
En este momento ya podemos arrancar Hive con start-metastore &. Con jobs verás algo así [1]+ Running start-metastore &. Si además queremos confirmar que está escuchando en el puerto indicado, podemos hacerlo con sudo netstat -tulpn | grep LISTEN. Para detener Hive, tanto kill <pid> como kill %job_id bastarán.
Con todo listo, llega el momento de instalar Trino en el clúster.
Además de la instalacion, Trino requiere de una configuración tanto en el coordinator como en los workers). Parte de esta configuración es común y otra es específica por tipo de nodo, aunque no es extraño mantener una única configuración por consistencia entre todos los nodos del clúster (esto es que aunque una propiedad no sea tenida en cuenta en un nodo, igualmente esté… no tengo claro que me guste del todo esto):
jvm.configconfig.propertiesnode.propertiescatalog/A_CATALOG.propertiesOTHER_CATALOG.properties- etc
Los ficheros dentro de catalog/ son los orígenes de datos a los que tendrá acceso Trino. Por ejemplo, para acceder a la cuenta de almacenamiento de Azure crearemos un fichero adls.properties siguiendo la documentación del conector:
connector.name=hive-hadoop2
hive.metastore.uri=thrift://YOUR_PRIVATE_IP_WHERE_HIVE_IS_RUNNING:9083
hive.azure.abfs.oauth.endpoint=YOUR_OAUTH_20_TOKEN_ENDPOINT_V1
hive.azure.abfs.oauth.client-id=YOUR_CLIENT_ID
hive.azure.abfs.oauth.secret=YOUR_SECRET
hive.allow-drop-table=true
Si el origen fuera SQL Server, el fichero <YOUR_CATALOG>.properties sería algo así:
connector.name=sqlserver
connection-url=jdbc:sqlserver://YOUR_SERVER:1433;database=YOUR_DATABASE
connection-user=YOUR_USER
connection-password=YOUR_PASSWORD
Si quieres que Trino cante, la gallina por delante.
Respecto a la memoria asignada a Trino, la documentación sugiere unos valores predeterminados, pero lógicamente puedes ajustarlos según tu tipo de workload (concurrencia, rendimiento, etc.). En este otro enlace apuestan por subir ligeramente la memoria asignada. A modo de resumen, la configuración más relevante en relación al uso de la memoria podría ser esta (aunque como podrás imaginar hay otras muchas propiedades).
| Fichero | Propiedad | Descripción |
|---|---|---|
| jvm.config | -Xmx##G | 80% de la memoria del nodo. |
| config.properties | query.max-memory | La cantidad máxima de memoria que puede usar una consulta en todo el clúster.Número de nodos worker * query.max-total-memory-per-node |
| config.properties | query.max-memory-per-node | La cantidad máxima de memoria que puede usar una consulta en un nodo.-Xmx##G * 0.2 |
| config.properties | query.max-total-memory-per-node | La cantidad máxima de memoria de usuario y de sistema (que no controla Trino) que puede usar una consulta en un nodo.-Xmx##G * 0.3 |
Si no has cambiado el tamaño de los nodos en el fichero cluster.sh, quizás quieras subirlos de tamaño (a mí me ha pasado varias veces), con este script podemos hacerlo de forma conjunta:
#!/bin/bash
size=NEW_SIZE
az vm resize --resource-group rg-trino --name vm-coordinator --size $size
for worker in {1..2}
do
az vm resize --resource-group rg-trino --name vm-worker$worker --size $size
done
Teniendo un clúster de 3 nodos del tamaño Standard_DS3_v2 (14GB).
jvm.config
-server
-Xmx11G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
-Djdk.attach.allowAttachSelf=true
config.properties (coordinator)
coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=8080
query.max-memory=4GB
query.max-memory-per-node=2GB
query.max-total-memory-per-node=3GB
discovery-server.enabled=true
discovery.uri=http://localhost:8080
spill-enabled=true
spiller-spill-path=/home/azureuser/spilling
config.properties (worker)
coordinator=false
http-server.http.port=8080
query.max-memory=4GB
query.max-memory-per-node=2GB
query.max-total-memory-per-node=3GB
discovery.uri=http://YOUR_PRIVATE_COORDINATOR_IP:8080
spill-enabled=true
spiller-spill-path=/home/azureuser/spilling
Antes de copiar la configuración, instalaremos Trino en el clúster con install_trino.sh
#!/bin/bash
password=YOUR_PASSWORD
coordinator_public_ip=YOUR_PUBLIC_COORDINATOR_IP
sshpass -p $password scp -r -o StrictHostKeyChecking=no install_trino_coordinator.sh azureuser@$coordinator_public_ip:/home/azureuser/
sshpass -p $password ssh -o StrictHostKeyChecking=no azureuser@$coordinator_public_ip 'chmod +x install_trino_coordinator.sh;./install_trino_coordinator.sh'
workers_public_ips=(YOUR_PUBLIC_WORKER_1_IP, YOUR_PUBLIC_WORKER_2_IP)
for worker_public_ip in "${workers_public_ips[@]}"
do
sshpass -p $password scp -r -o StrictHostKeyChecking=no install_trino_worker.sh azureuser@$worker_public_ip:/home/azureuser/
sshpass -p $password ssh -o StrictHostKeyChecking=no azureuser@$worker_public_ip 'chmod +x install_trino_worker.sh;./install_trino_worker.sh'
done
install_coordinator.sh
#!/bin/bash
wget -q https://repo1.maven.org/maven2/io/trino/trino-server/360/trino-server-360.tar.gz -O trino-server-360.tar.gz
tar -xzvf trino-server-360.tar.gz
mkdir trino-server-360/etc
wget -q https://repo1.maven.org/maven2/io/trino/trino-cli/360/trino-cli-360-executable.jar -O trino-cli-360-executable.jar
mv trino-cli-360-executable.jar trino-server-360/trino
sudo chmod +x trino-server-360/trino
echo 'export PATH=$PATH:~/trino-server-360' >> .bashrc
install_worker.sh
#!/bin/bash
wget -q https://repo1.maven.org/maven2/io/trino/trino-server/360/trino-server-360.tar.gz -O trino-server-360.tar.gz
tar -xzvf trino-server-360.tar.gz
mkdir trino-server-360/etc
Después de instalar Trino, copiaremos la configuración desde local con configuration.sh (que es cómodo porque podemos cambiarla en local y actualizar todo los nodos del clúster ejecutando este fichero en local):
#!/bin/bash
password=YOUR_PASSWORD
coordinator_public_ip=YOUR_PUBLIC_COORDINATOR_IP
sshpass -p $password scp -r -o StrictHostKeyChecking=no vm-coordinator/* azureuser@$coordinator_public_ip:/home/azureuser/trino-server-360/etc/
workers_public_ips=(YOUR_PUBLIC_WORKER_1_IP, YOUR_PUBLIC_WORKER_2_IP)
for worker_public_ip in "${workers_public_ips[@]}"
do
sshpass -p $password scp -r -o StrictHostKeyChecking=no vm-worker/* azureuser@$worker_public_ip:/home/azureuser/trino-server-360/etc/
done
El fichero de configuración node.properties es distinto por nodo del clúster (node.id es un GUID y tiene que ser siempre el mismo aunque se reinicia el servidor), así que nos va tocar crearlo a mano en cada nodo:
node.environment=dev/testing
node.id=071e53fd-0f92-45d2-acd3-973ddf4b504e
node.data-dir=/home/azureuser/trino-server-360/data
Ahora que está todo listo y tenemos que ejecutar Trino en todos los nodos, podemos usar MobaXterm y su característica MultiExec para ejecutar el comando trino-server-360/bin/launcher start:
Si todo ha ido bien, en http://YOUR_COORDINATOR_PUBLIC_IP:8080 podrás acceder a Trino y ver que el clúster está levantando.
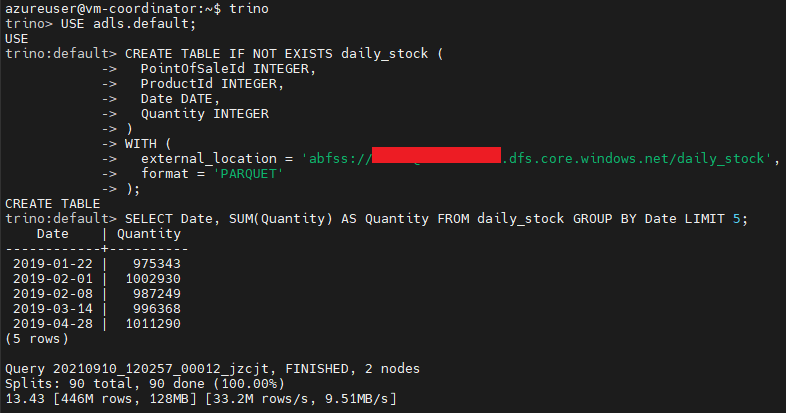
Para probar que podemos acceder a los ficheros de nuestra cuenta de almacenamiento, ejecuta el cliente trino desde el coordinator y crea una tabla que apunte al directorio adecuado (en el caso de SQL Server todo esto no es necesario, las tablas ya estarán listas):
USE adls.default;
CREATE TABLE IF NOT EXISTS daily_stock (
PointOfSaleId INTEGER,
ProductId INTEGER,
Date DATE,
Quantity INTEGER
)
WITH (
external_location = 'abfss://YOUR_CONTAINER@YOUR_STORAGE_ACCOUNT.dfs.core.windows.net/daily_stock',
format = 'PARQUET'
);
SELECT Date, SUM(Quantity) AS Quantity FROM daily_stock GROUP BY Date LIMIT 5;
Como último apunte, ahora mismo en Trino ni el servidor es seguro (http) ni hay seguridad de usuarios. Usar un fichero de usuarios/contraseñas en el servidor no parece lo mejor opción, pero podría ser suficiente en un entorno de dev/testing. Con htpasswd -c -B -C 10 trino-server-360/etc/password.db azureuser podemos generar el fichero de usuarios/contraseñas y en cuanto a https, podemos generar un certificado auto-firmado con las siguientes instrucciones:
openssl req -x509 -newkey rsa:4096 -keyout key.pem -out cert.pem -days 365 -nodes
cat key.pem cert.pem > clustercoord.pem
Para hacer efectiva la seguridad, hay que modificar el fichero config.properties:
http-server.authentication.type=PASSWORD
http-server.https.enabled=true
http-server.https.port=8443
http-server.https.keystore.path=/home/azureuser/trino-server-360/clustercoord.pem
Y añadir el fichero password-authenticator.properties:
password-authenticator.name=file
file.password-file=/home/azureuser/trino-server-360/etc/password.db
Un saludo!